字符和编码
Contents
引言
计算机中的存储器唯一可以存储的是bit(0/1),如果想要在计算机上处理信息,就必须把它按位存储。因此为了将文本表示为数字形式,我们需要构建一个系统来为每一个字符赋予一个独一无二的ID。
具有这种功能的系统被称为字符集(Charset。其实字符集就是一个map,一个字符到表示这个字符的唯一ID[这些Id就被称作码点(code point)]的映射集合。有了字符集合我们就将文本映射成数字形式。但是需要一个规则用来规定如何在计算机中存储这些数字(使用多少字节?),于是我们就有了字符编码(encoding)。
ASCII
在计算机早期应对的字符场景还很简单(大小写拉丁字母(26 * 2 = 52) + 数字0-9(10) + 一些符号 不超过128个),因此于1963年发布的ASCII是可以应付当时的场景。
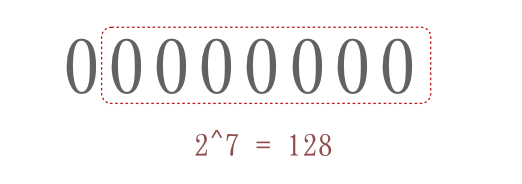
标准ASCII只用到的1byte的后7位。看下图就可以知道ASCII使用范围是$0x00$ ~ $ 0x7F$。

Unicode
随着计算机的发展和互联网的普及,计算机需要面对各个国家的语言。此时ASCII很显然无法满足需求了,于是各个国家都发布了自己语言的字符集,我们国家也是在1980年发布了基于ASCII扩展的中文字符集GB2312。
于是建立一个涵盖世界上所有文本的编码规范成为了一个迫切的需求。在国际化标准组织和美国几大商业公司合作下,1991年Unicode发布。
最初的Unicode编码使用16位的编码空间也就是2Byte这样理论上最多可以表示$2^{16}$(即65536)个字符,显然这样要表示世界上所有语言中的字符是远远不够的。后来在Unicode4.0规范中考虑到了这种情况,定义了一组附加字符编码,附加字符编码使用2个16位表示,也就是4byte。目前Unicode编码范围是U+0000~U+10FFFF。
Unicode将这些码点按照每组$2^{16}$(65536)分组,每组被称为一个平面(plane)。一共将这些码点分成了17个平面,Plane0 ~ Plane16。Plane0又被称作基本多文本平面(BMP),其他平面统称为辅助平面。
| 平面 | 范围 | 中文名称 | 英文名称 |
|---|---|---|---|
| 0号平面(Plane0) | U+0000 - U+FFFF | 基本多文本平面 | BMP |
| 1号平面(Plane1) | U+10000 - U+1FFFF | 多文种补充平面 | SMP |
| 2号平面(Plane2) | U+20000 - U+2FFFF | 表意文字补充平面 | SIP |
| 3号平面(Plane3) | U+30000 - U+3FFFF | 表意文字第三平面 | TIP |
| 4号平面~13号平面 | U+40000 - U+DFFFF | 未使用 | |
| 14号平面(Plane14) | U+E0000 - U+EFFFF | 特别用途补充平面 | SSP |
| 15号平面(Plane15) | U+F0000 - U+FFFFF | 保留作为私人使用区(A区) | PUA-A |
| 16号平面(Plane16) | U+100000 - U+10FFFF | 保留作为私人使用区(B区) | PUA-B |
Unicode编码方案
Unicode 没有规定字符对应的二进制码如何存储。以汉字“汉”为例,它的 Unicode 码点是 0x6c49,对应的二进制数是 110110001001001,二进制数有 15 位,这也就说明了它至少需要 2 个字节来表示。可以想象,在 Unicode 字典中往后的字符可能就需要 3 个字节或者 4 个字节,甚至更多字节来表示了。
这就导致了一些问题,计算机怎么知道你这个 2 个字节表示的是一个字符,而不是分别表示两个字符呢?这里我们可能会想到,那就取个最大的,假如 Unicode 中最大的字符用 4 字节就可以表示了,那么我们就将所有的字符都用 4 个字节来表示,不够的就往前面补 0(UTF-32)。这样确实可以解决编码问题,但是却造成了空间的极大浪费,如果是一个英文文档,那文件大小就大出了 3 倍,这显然是无法接受的。
于是,为了较好的解决 Unicode 的编码问题, UTF-8 和 UTF-16 两种当前比较流行的编码方式诞生了。当然还有一个 UTF-32 的编码方式,也就是上述那种定长编码,字符统一使用 4 个字节,虽然看似方便,但是却不如另外两种编码方式使用广泛。
UTF-8
UTF-8 是一个非常惊艳的编码方式,漂亮的实现了对 ASCII 码的向后兼容,以保证 Unicode 可以被大众接受。
UTF-8 是目前互联网上使用最广泛的一种 Unicode 编码方式,它的最大特点就是可变长。它可以使用 1 - 4 个字节表示一个字符,根据字符的不同变换长度。编码规则如下:
- 对于单个字节的字符,第一位设为 0,后面的 7 位对应这个字符的 Unicode 码点。因此,对于英文中的 0 - 127 号字符,与 ASCII 码完全相同。这意味着 ASCII 码那个年代的文档用 UTF-8 编码打开完全没有问题。
- 对于需要使用 N 个字节来表示的字符(N > 1),第一个字节的前 N 位都设为 1,第 N + 1 位设为 0,剩余的 N - 1 个字节的前两位都设位 10,剩下的二进制位则使用这个字符的 Unicode 码点来填充。
编码规则如下:
| Unicode 十六进制码点范围 | UTF-8 二进制 |
|---|---|
| 0000 0000 - 0000 007F | 0xxxxxxx |
| 0000 0080 - 0000 07FF | 110xxxxx 10xxxxxx |
| 0000 0800 - 0000 FFFF | 1110xxxx 10xxxxxx 10xxxxxx |
| 0001 0000 - 0010 FFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx |
Unicode 和 UTF-8 之间的转换关系表 ( x 字符表示码点占据的位 )如下:
| 码点的位数 | 码点起值 | 码点终值 | 字节序列 | Byte 1 | Byte 2 | Byte 3 | Byte 4 |
|---|---|---|---|---|---|---|---|
| 7 | U+0000 | U+007F | 1 | 0xxxxxxx |
|||
| 11 | U+0080 | U+07FF | 2 | 110xxxxx |
10xxxxxx |
||
| 16 | U+0800 | U+FFFF | 3 | 1110xxxx |
10xxxxxx |
10xxxxxx |
|
| 21 | U+10000 | U+1FFFFF | 4 | 11110xxx |
10xxxxxx |
10xxxxxx |
10xxxxxx |
编码过程
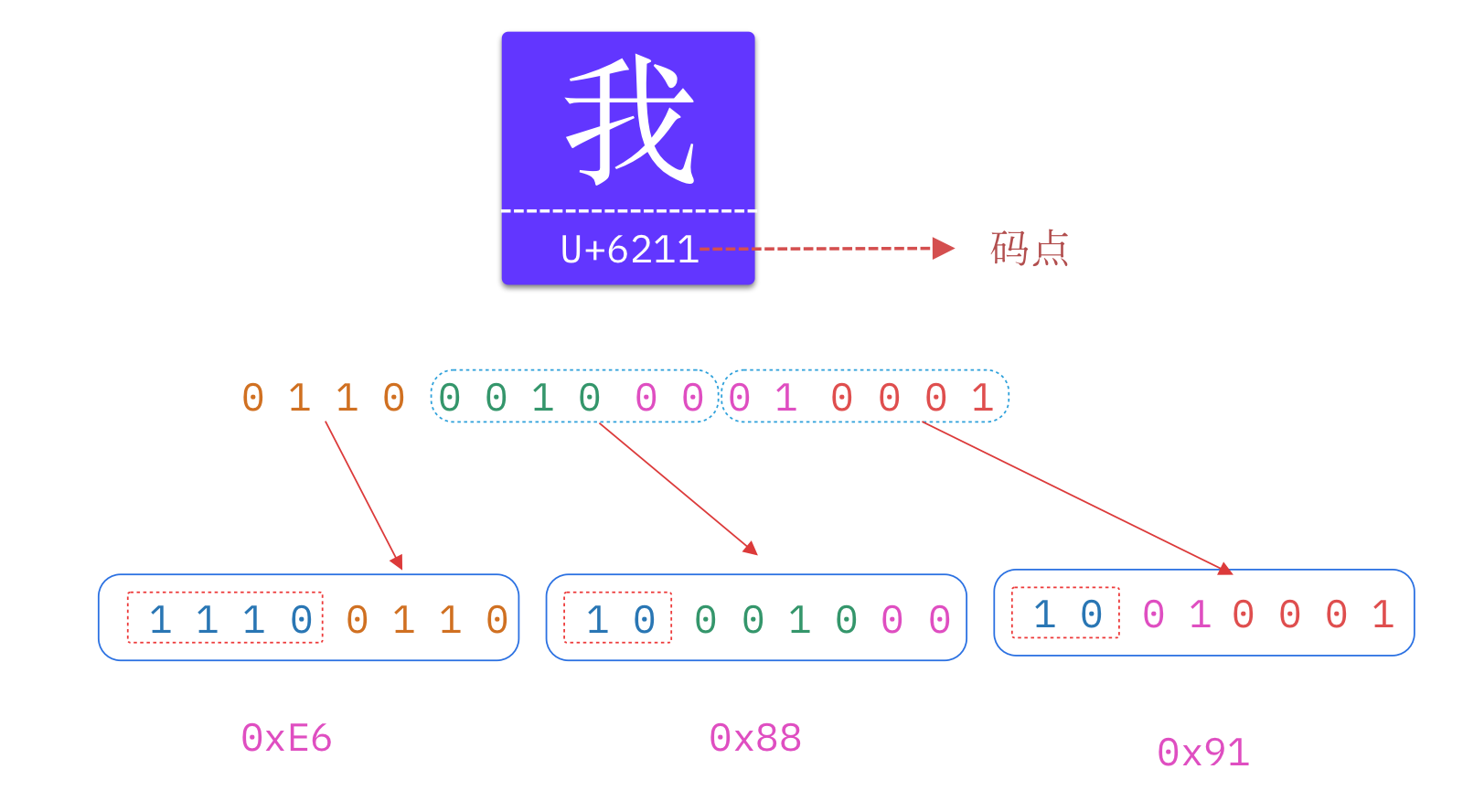
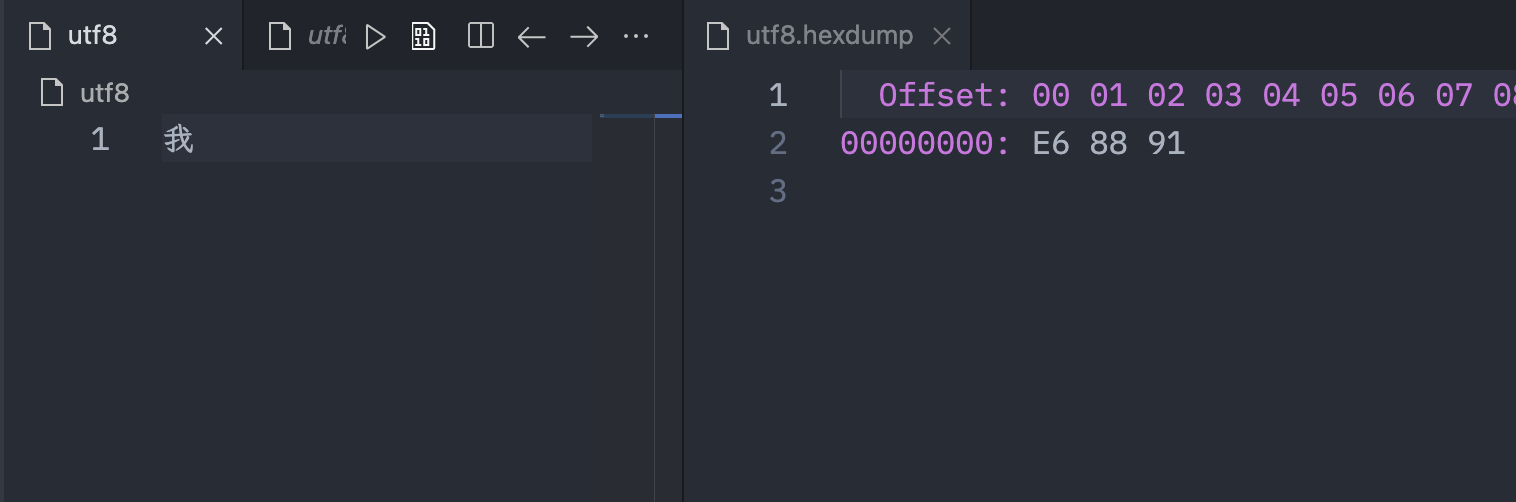
下图展示了中文“我”的UTF-8的编码过程,最终得到的结果是0xE68891
UTF-16
UTF-16 编码介于 UTF-32 与 UTF-8 之间,同时结合了定长和变长两种编码方法的特点。它的编码规则很简单:基本平面的字符占用 2 个字节,辅助平面的字符占用 4 个字节。也就是说,UTF-16 的编码长度要么是 2 个字节(U+0000 到 U+FFFF),要么是 4 个字节(U+010000 到 U+10FFFF)。那么问题来了,当我们遇到两个字节时,到底是把这两个字节当作一个字符还是与后面的两个字节一起当作一个字符呢?
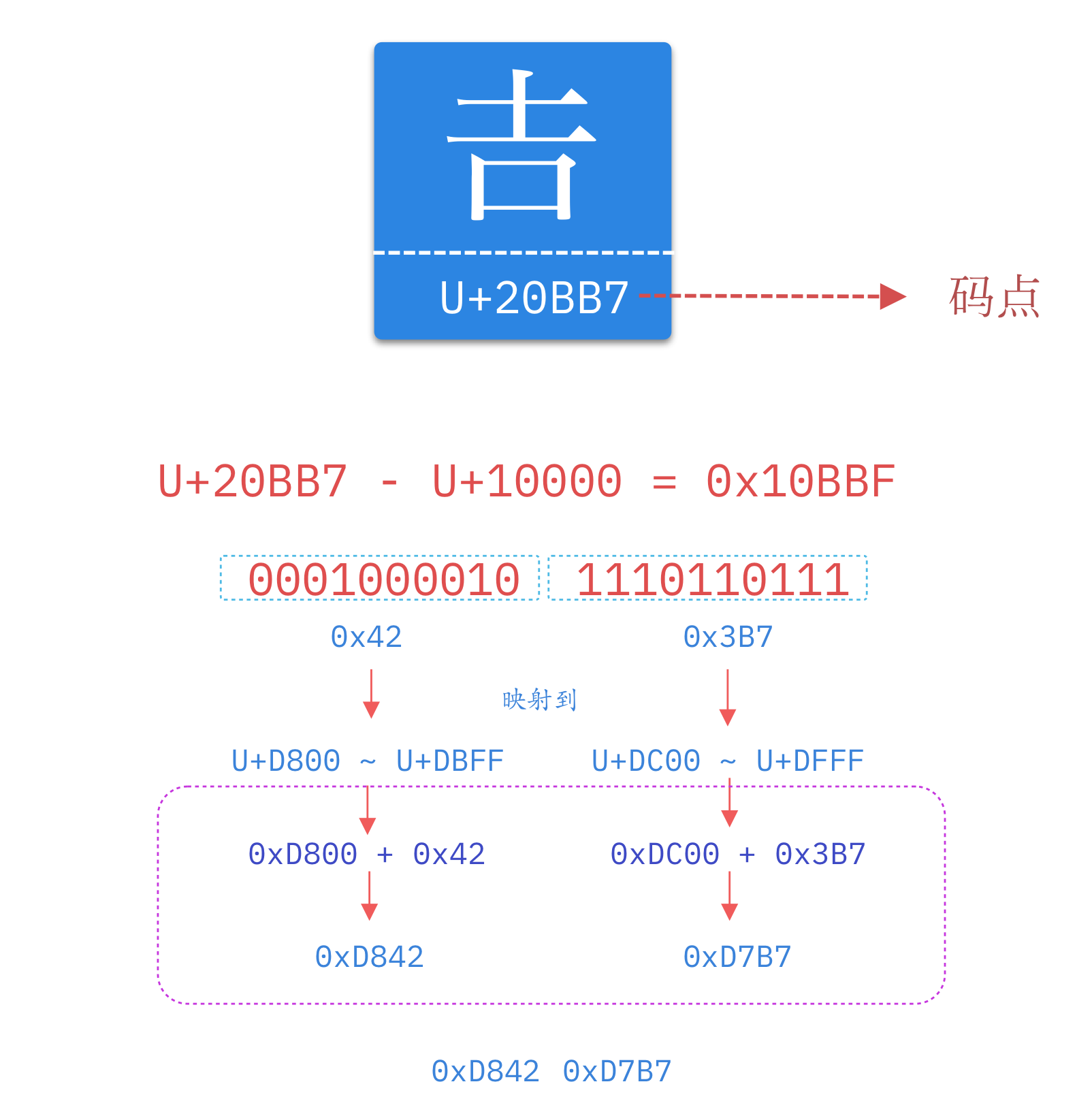
这里有一个很巧妙的地方,在基本平面内,从 U+D800 到 U+DFFF ($2^{11}$)是一个空段,即这些码点不对应任何字符。因此,这个空段可以用来映射辅助平面的字符。
辅助平面的字符位共有 $2^{20}$ 个,因此表示这些字符至少需要 20 个二进制位。UTF-16 将这 20 个二进制位分成两半,前 10 位映射在 U+D800 到 U+DBFF(空间大小 $2^{10}$),称为高位(H),后 10 位映射在 U+DC00 到 U+DFFF(空间大小 $2^{10}$),称为低位(L)。这意味着,一个辅助平面的字符,被拆成两个基本平面的字符表示。
因此,当我们遇到两个字节,发现它的码点在 U+D800 到 U+DBFF 之间,就可以断定,紧跟在后面的两个字节的码点,应该在 U+DC00 到 U+DFFF 之间,这四个字节必须放在一起解码。
编码过程
下面以古汉字“𠮷”为例,展示下UTF-16编码过程。
BOM
我们到Vscode里验证下结果
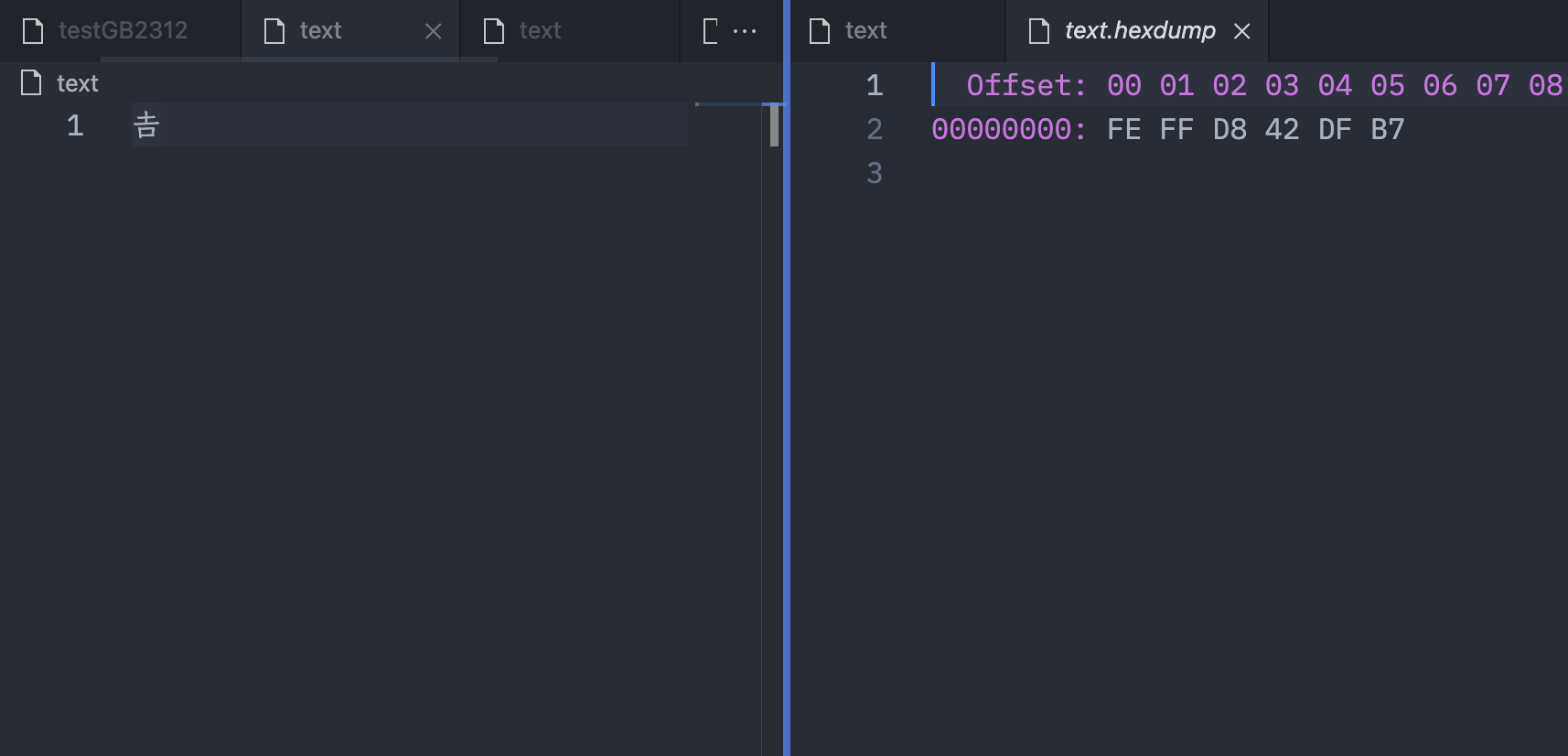
好像有点不对劲,我们看到多了两个字节0xFE和0xFF,这两个字节是干什么的呢?其实这两个字节是用来标识字节序的,有个官方称呼叫BOM(byte-order mark)。
其中UTF-16 BE(大端序) BOM为0xFE 0xFF, UTF-16 LE(小端序)BOM为0xFF 0xFE。
另外说一下 UTF-8也有BOM 0xEF 0xBB 0xBF (其实UTF-8并不需要BOM,尽管 Unicode 标准允许在 UTF-8 中使用 BOM。)
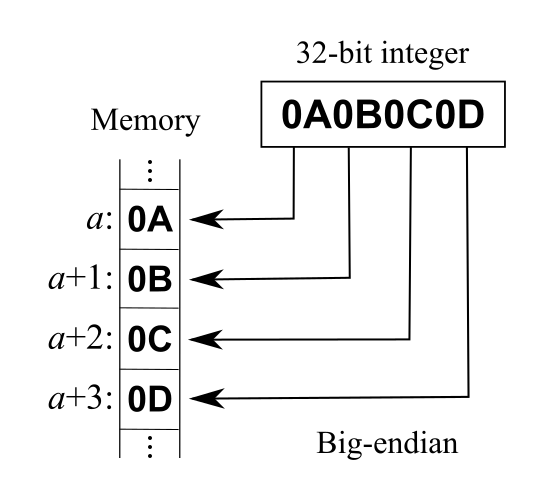
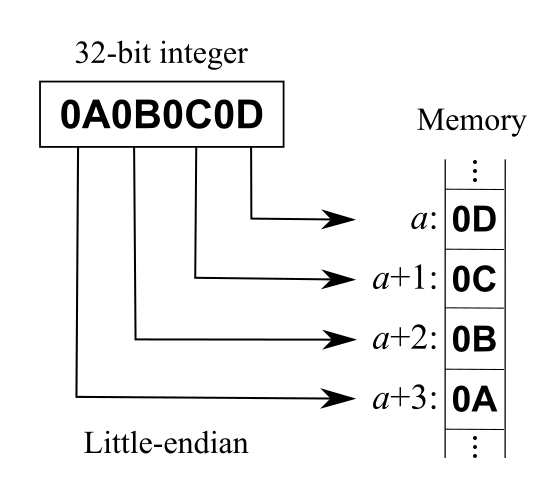
字节序
这里介绍下字节序,字节序用来表示多字节数据在内存中或者网络传输中各字节的存储顺序
JavaScript中字符函数的坑点
当字符串中字符都在基本多文本平面范围外,String的某些方法会得到一个令人意外的值。下面还是以下面古汉字“𠮷”为例。
1 | /** String.prototype.length获取的并不是字符个数而是code unit的长度。 |
上面代码表示,JavaScript 认为字符的长度是 2,取到的第一个字符的码点是 0xDB34。这些结果都不正确!
解决这个问题,必须对码点做一个判断,然后手动调整。下面是正确的遍历字符串的写法。
1 | while (++index < length) { |
类似的问题存在于所有的 JavaScript 字符操作函数。
1 | String.prototype.replace() |
上面的函数都只对 2 字节的码点有效。要正确处理 4 字节的码点,就必须逐一部署自己的版本,判断一下当前字符的码点范围。
ECMAScript 6 中对 Unicode 的扩展
字符的 Unicode 表示法
ES6 加强了对 Unicode 的支持,允许采用\uxxxx 形式表示一个字符,其中 xxxx 表示字符的 Unicode 码点。
1 | "\u0061" |
但是,这种表示法只限于码点在\u0000~\uFFFF 之间的字符。超出这个范围的字符,必须用两个双字节的形式表示。
1 | "\uD842\uDFB7" |
上面代码表示,如果直接在\u 后面跟上超过 0xFFFF 的数值(比如\u20BB7),JavaScript 会理解成\u20BB+7。所以会显示一个其他字符,后面跟着一个 7。
ES6 对这一点做出了改进,只要将码点放入大括号,就能正确解读该字符。
1 | "\u{20BB7}" |
上面代码中,最后一个例子表明,大括号表示法与四字节的 UTF-16 编码是等价的。
有了这种表示法之后,JavaScript 共有 6 种方法可以表示一个字符。
1 | '\z' === 'z' // true |
字符串的遍历器接口
ES6 为字符串添加了遍历器接口,使得字符串可以被 for…of 循环遍历。
1 | for (let codePoint of 'foo') { |
除了遍历字符串,这个遍历器最大的优点是可以识别大于 0xFFFF 的码点,传统的 for 循环无法识别这样的码点。
REPLACEMENT CHARACTER �
1 | let text = String.fromCodePoint(0x20BB7); |
上面代码中,字符串 text 只有一个字符,但是 for 循环会认为它包含两个字符(都不可打印),而 for…of 循环会正确识别出这一个字符。
直接输入 U+2028 和 U+2029
JavaScript 字符串允许直接输入字符,以及输入字符的转义形式。举例来说,“中”的 Unicode 码点是 U+4e2d,你可以直接在字符串里面输入这个汉字,也可以输入它的转义形式\u4e2d,两者是等价的。
1 | '中' === '\u4e2d' // true |
但是,JavaScript 规定有 5 个字符,不能在字符串里面直接使用,只能使用转义形式。
- U+005C:反斜杠(reverse solidus)
- U+000D:回车(carriage return)
- U+2028:行分隔符(line separator)
- U+2029:段分隔符(paragraph separator)
- U+000A:换行符(line feed)
举例来说,字符串里面不能直接包含反斜杠,一定要转义写成\或者\u005c。
这个规定本身没有问题,麻烦在于 JSON 格式允许字符串里面直接使用 U+2028(行分隔符)和 U+2029(段分隔符)。这样一来,服务器输出的 JSON 被 JSON.parse 解析,就有可能直接报错。
1 | const json = '"\u2028"'; |
JSON 格式已经冻结(RFC 7159),没法修改了。为了消除这个报错,ES2019 允许 JavaScript 字符串直接输入 U+2028(行分隔符)和 U+2029(段分隔符)。
const PS = eval(“‘\u2029’”); 根据这个提案,上面的代码不会报错。
注意,模板字符串现在就允许直接输入这两个字符。另外,正则表达式依然不允许直接输入这两个字符,这是没有问题的,因为 JSON 本来就不允许直接包含正则表达式。
JSON.stringify() 的改造
根据标准,JSON 数据必须是 UTF-8 编码。但是,现在的 JSON.stringify()方法有可能返回不符合 UTF-8 标准的字符串。
具体来说,UTF-8 标准规定,0xD800 到 0xDFFF 之间的码点,不能单独使用,必须配对使用。比如,\uD834\uDF06 是两个码点,但是必须放在一起配对使用,代表字符 𝌆。这是为了表示码点大于 0xFFFF 的字符的一种变通方法。单独使用\uD834 和\uDFO6 这两个码点是不合法的,或者颠倒顺序也不行,因为\uDF06\uD834 并没有对应的字符。
JSON.stringify()的问题在于,它可能返回 0xD800 到 0xDFFF 之间的单个码点。
1 | JSON.stringify('\u{D834}') // "\u{D834}" |
为了确保返回的是合法的 UTF-8 字符,ES2019 改变了 JSON.stringify()的行为。如果遇到 0xD800 到 0xDFFF 之间的单个码点,或者不存在的配对形式,它会返回转义字符串,留给应用自己决定下一步的处理。
1 | JSON.stringify('\u{D834}') // ""\\uD834"" |
字符串处理函数
ES6 新增了几个专门处理 4 字节码点的函数。
String.fromCodePoint():从 Unicode 码点返回对应字符
因为 fromCodePoint() 是 String 的一个静态方法,所以只能通过 String.fromCodePoint() 这样的方式来使用,不能在你创建的 String 对象实例上直接调用。
1 | String.fromCodePoint(42); // "*" |
String.prototype.codePointAt():从字符返回对应的码点
1 | console.log('Є'.codePointAt(0)) |
正则表达式
ES6 提供了 u 修饰符,对正则表达式添加 4 字节码点的支持。
1 | /^.$/.test('𝌆') |
Unicode 正规化
有些字符除了字母以外,还有附加符号。比如,汉语拼音的 Ǒ,字母上面的声调就是附加符号。对于许多欧洲语言来说,声调符号是非常重要的。
Unicode 提供了两种表示方法。一种是带附加符号的单个字符,即一个码点表示一个字符,比如 Ǒ 的码点是 U+01D1;另一种是将附加符号单独作为一个码点,与主体字符复合显示,即两个码点表示一个字符,比如 Ǒ 可以写成 O(U+004F) + ˇ(U+030C)。
1 | // 方法一 |
这两种表示方法,视觉和语义都完全一样,理应作为等同情况处理。但是,JavaScript 无法辨别。
1 | '\u01D1'==='\u004F\u030C' |
ES6 提供了 normalize 方法,允许”Unicode 正规化”,即将两种方法转为同样的序列。
1 | '\u01D1'.normalize() === '\u004F\u030C'.normalize() |